情報基礎A 「Cプログラミング」(ステップ7・配列)
このステップの目標
- 配列変数を用い、配列要素への適正なアクセスに配慮したプログラムが書ける
- 計算によってアクセス位置を変えたり、配列要素の並べ替え操作を伴う処理、および「総和のパターン」のプログラムが書ける
1.配列変数の基本
コンピュータを使って大量のデータを処理するために必須の機能のひとつ、それが配列だ。 「プログラミングの入門編」といえども、この配列は是非マスターしておきたい。
 配列変数:沢山のメモリー(変数)を一括して確保し、通し番号でアクセスする
配列変数:沢山のメモリー(変数)を一括して確保し、通し番号でアクセスする
これまで書いてきたプログラムでは、変数が必要になったら、その都度、名前を付けて、
int are ; float kore ;
のように宣言していた。 ところが、例えば、1000人から成る集団があって、それぞれの情報(例えば体重)を使った処理をしたいような場合、同じような変数宣言を1000回も書くのは御免こうむりたい。 このように、データの件数が多い場合(あるいは、データの件数が不定の場合)には、必要な個数のメモリを一括して宣言し、それぞれを通し番号(**番目)で管理するのが理にかなっている。
C言語に限らず、一般のプログラミング言語では、こうした用途に使うために、配列型のデータ構造(array data type)が用意されている。
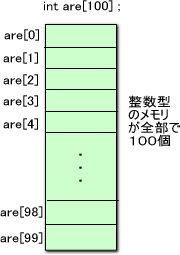
例えば、int型の変数を100個、float型の変数を1000個分、一括して準備したい場合は、
int are[100] ; float kore[1000] ;
のように宣言する。括弧[ ]の中には、必要な変数の個数を記述する。
配列変数へのアクセス
これらの変数の中身(データ)には、通し番号を付け、要素ごとにアクセスする。例えば、
are[3] = 17 ; kore[ i ] = kore [ i-1 ] + kore [ i+1 ] ;
のように。つまり [ ] の中に、何番目のハコであるかを指定するわけだ。 ハコの場所は、整数値で指定しても良いし、変数や数式であっても構わない。
配列へのアクセスの「はみ出し」は、コンパイル時には検出できないので、とても厄介だ。
ここで、気をつけなければならないのは、通し番号は0から始まることだ。
100個の要素から成る配列を宣言したら、おしまいの要素の番号は99である(図参照)
あらかじめ宣言した範囲を超えた要素(例えば kore[-1]やkore[100])にアクセスすると、
プログラムは『予期せぬ動作』をするので、十分注意すること。
配列データのコピー
標準的なCの処理系には、連続したデータをコピーするためmemcpy()関数等が用意されており、
実際のプログラミングではそちらを使う場合も多い。
配列変数の中身をそっくりコピーする場合、
int a[100],b[100] ; ・・・ a = b ;
のように書いてはいけない。「配列へのアクセスは要素ごとに行う」のが基本ルールである。 であるから、面倒だけれども、
int a[100],b[100] ; int i ; ・・・ for (i=0; i<100; i=i+1) a[i] = b[i] ;
のように、反復処理を使って、要素毎に逐一代入する必要がある。
2.配列を使ったデータ処理(最大値・最小値、ソーティング、二分探索)
#define N 10
以下に示す例題プログラムでは、宣言部に #define N 10 とある。
これは、『これ以降では N と書いたら、それは 10 と書いたことと見なす(Nを10と定義する)』という宣言である。
したがって、float x[N] は float x[10] を、for (i=0;i<N;i=i+1)はfor (i=0;i<10;i=i+1)を、それぞれ意味する。このNは変数ではないので注意すること。
例1:最大値・最小値
数値計算や、統計処理などを行う際に、あらかじめ配列にデータをセットしておいてから、あれこれ計算を進めるのが効率的である。 そんな際に、配列中のデータの中で一番大きな値が必要になることがよくある。 以下は、配列中の最大値を見つけるプログラムの例である。
例題8(ex8.c)
配列中のデータの中から最大値を探し出す。
#include <stdio.h>
#define N 10
main( )
{
float x[N] = { 2.1, 5.3, 7.3, 4.7, 9.2, 1.2, 3.1, 5.3, 8.3, 4.8 } ;
int i ;
float maxval ;
maxval = x[0] ;
for (i=1 ; i<N ; i=i+1) {
if (x[i] > maxval) {
maxval = x[i] ;
}
}
printf ("最大値= %f\n",maxval) ;
}
プログラムの見所
配列変数の初期化
配列変数の初期値を設定する場合に、いちいち、
x[0] = 2.1 ; x[1] = 5.3 ;
のように書くのは手間がかかるので、上記の例のように、まとめて
のような書き方が許されている。ただし、この 配列[ ]={ }; の記法は変数宣言の際にだけ(最初の1回だけ)使うことができる。
配列データの中から最大値を探す手順
8行目から16行目にかけてが、配列の中から最大値を見つける処理。 基本的な考え方は、すでにステップ6で説明してあるので、そちらを参照のこと。 念のために、アルゴリズムを言葉で表現すると:
1: 仮の最大値として、最初の要素の値を設定する(仮の最大値は、本当の最大値を超えない値ならば何でも良い) 2: 配列の中身を順に最後まで調べる: 3: もし、i番目の値が、仮の最大値より大きければ、仮の最大値としてi番目の値をセットする 4: この時点での、仮の最大値を、配列全体を通しての最大値とする
上の手順をちょっとだけ変更すれば、最小値を見つけるアルゴリズムになる。
例2:データの整列(ソーティング)
次に、もう少し複雑な処理の例として、 配列中の数値の並び順を、小さい方から大きい方へ順に(昇順に)並べ変え、出力するプログラムを示す:
例題9(ex9.c)
![]()
配列データの整列(ソーティング)
#include <stdio.h>
#define N 10
main( )
{
float x[N] = { 2.1, 5.3, 7.3, 4.7, 9.2, 1.2, 3.1, 5.3, 8.3, 4.8 } ;
int i,j ;
float w ;
for (i=0 ; i<N-1 ; i=i+1) {
for (j=N-1 ; j>i ; j=j-1) {
if (x[j-1]>x[j]) {
w = x[j] ;
x[j] = x[j-1] ;
x[j-1] = w ;
}
}
}
for (i=0; i<N ; i=i+1) {
printf("%f\n",x[i]) ;
}
}
例題 9のアルゴリズム
Input: 10件のデータが入った配列 $\{x_i\}$
Output: 昇順に整列された配列 $\{x_i\}$
1: 配列$\{x_i\}$に10件のデータをセットする
2: 位置 $i$ を、先頭から末尾から1つ前まで、1ずつ「後方に」移動しながら、6:までを繰り返す:
3: 位置 $j$ を、末尾から $i+1$ まで、1ずつ「前に」移動しながら、5:までを繰り返す:
4: もし 隣同士が $x_{j-1} \gt x_j$ ならば、$x_{j-1}$ と $x_j$ の値を入れ替える
5: 反復ここまで
6: 反復ここまで
7: 配列の値を先頭から順に出力する
8: 終了する
プログラムの見所
ソーティングについての 補足説明はこちら
例題9の8〜16行目にかけてが、配列データの並べ変え(整列、ソーティング)を行っている部分である。
$i$ のループの中に $j$ のループが入れ子になった2重ループを形成しており、$j$ は $i$ より大きな値の範囲を動くようになっている($0 \le i \lt j \le 9$)。
ここで、配列要素 x[j] で $x_j$ と表すと、
例題9では、隣り合う全ての $x_{j-1}$ と $x_{j}$ のペアを参照しながら、もし $x_{j-1} \gt x_j$ ならば値を入れ替える動作を繰り返している。
こうすることで、全ての$j$ について、最終的に $x_{j-1}\le x_j$ が成り立つようにできる。
これは、バブルソート(bubble sort)と呼ばれるアルゴリズムに基づいたソーティングの例である。
ソーティングの仕組みについては、別ページにもう少し詳しく説明した。 また、教科書 例題2.25 (p.30)も併せて参照のこと。
例3:データの検索(二分探索)
配列データの中に、ある値を持ったデータが含まれているかどうかを調べるには、添字を0から順に変えながら、値を比較すればよい。 データの件数が増えると、これは無視できない手間となる。 けれども、もしデータが既に(ここでは昇順に)整列済みの場合は、二分探索法(binary search algorithm)と呼ばれる、 シンプルながらも効率的なアルゴリズムが利用できる。
以下は、この二分探索を使って、キーボードから入力した数値が、配列xの中のどの区間(何番目の要素の間)に位置するかを調べ、表示するCプログラムの例である。 入力値を$v$とすると、$x_i \le v \lt x_{i+1}$ となるような $i, i+1$ が出力される。 このプログラムでは、N=10 件の既に昇順に整列済みの配列データを用いており、 データの最小値よりも小さい$v$を入力すると [-1,0] が、最大値より大きな$v$については [N-1, N] が出力される。
二分探索
#include <stdio.h>
#define N 10
main( )
{
float x[N] = { 1.2, 2.1, 3.1, 4.7, 4.8, 5.3, 5.3, 7.3, 8.3, 9.2 } ;
int i,il,ih ;
float val ;
printf("探したい値:") ;
scanf("%f",&val) ;
il=-1 ;
ih=N ;
for (;;) {
if (ih-il<=1) break ;
i = (ih + il)/2 ;
if (x[i]<=val) il=i ;
else ih=i ;
}
printf ("そのデータは %d 番目と %d 番目の要素の間に位置します\n",il,ih) ;
}
「二分探索」のアルゴリズム
Input: 10件のデータが昇順に入った配列 $\{x_i\}$ と探索する値 $v$
Output: $x_{i} \ge v \gt x_{i+1}$となるような $i, i+1$の組
1: 配列$\{x_i\}$に10件のデータをセットする
2: キーボードから値を$v$にセットする
3: 下端の位置を $i_l \leftarrow -1$ とする
4: 上端の位置を $i_h \leftarrow 10$
5: 下端と上端が接する($i_h - i_l \le 1$ となる)まで、9: までを繰り返す
6: 下端と上端の中間位置を $i$ にセットする( $i \leftarrow (i_h + i_l)/2$ )
7: もしも $x_i \lt v$ ならば、$i$を新しい下端とする($i_l \leftarrow i$)
8: そうでなければ、$i$を新しい上端とする($i_l \leftarrow i$)
9: 反復ここまで
10: 上端と下端の位置を出力する
11: 終了する
プログラムの見所
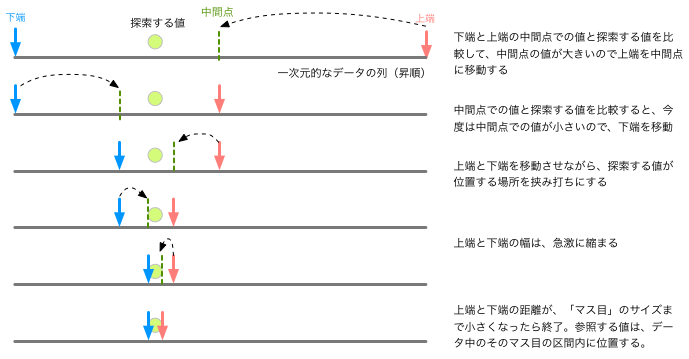
forループの箇所がこのコードの中心部分で、
変数ilを下端、ihを上端として、その中間位置i=(il+ih)/2での配列の値とデータを比較し、
その大小関係に応じて、下端または上端の位置を更新している。
いわば、『挟み打ち』にする作戦である(下図)。
地下に埋設されたケーブルのどこかに不具合があったとき、全体を掘り返す代わりに、まず問題のある区間の中間点を掘ってみて、 問題箇所がその上流側が下流側かを調べ、調べる区間を狭める。 こうした作業を繰り返せば、短時間で問題箇所を特定できるはずである。
 練習:データの整列
練習:データの整列
例題9(ex9.c)のコードに変更を加え、以下の80件のデータ(東北楽天ゴールデンイーグルスに登録されている選手の身長)の並びについて、値が大きいものから小さくなる順(降順)に整列されるよう改修してみなさい。
float x[80] = {
174,175,180,185,178,184,179,185,170,178,184,183,180,191,180,180,174,188,181,182,
187,178,175,177,185,178,175,175,174,169,174,173,185,178,180,180,183,191,179,178,
174,185,185,180,193,181,178,181,177,176,174,180,186,180,180,180,185,174,194,175,
183,176,192,185,186,193,171,172,175,186,180,172,175,175,177,181,178,180,176,174};
 ヒント
ヒント
昇順から降順に切り替えるには、プログラム中の1箇所を変更するのみである。 データの件数が変わると、プログラムのどの箇所が影響されるかについても、よく考えること。
練習:平均とメジアン
上の課題(「データの整列」)で作成したプログラムにさらにコードを追加し、以下の例に倣って、平均値と中央値(median)を出力するよう改修してみなさい。
... 172 172 169 平均身長= ... 中央値= ...
ヒント
平均の計算は、このページの例題6A(ex6a.c)を参照のこと。
練習:バブルソートに要する手間
バブルソートを行なう際に、その「手間」あるいは「工数」を見積もる指標として
- A. 隣同士のデータの大小を比較する回数
- B. 隣同士のデータを入れ替える回数
を考えるのが良さそうである。もちろん、回数が少ないほど効率よく短時間で仕事が完了するはずである。 上の データの整列 で作成したプログラムを元にして、1,2の回数をプログラム内でカウントし、
比較の回数= xxx回 入れ替えの回数 xxx回
のように出力するプログラムを作成しなさい。
3.配列を使った統計計算
前のステップで行った統計計算プログラムを、配列を使ったバージョンに変更してみよう。 先にまず、全データを配列変数に格納して、その後で、平均の計算を行っている。 配列変数が登場する以外には、特に目新しい箇所は無いはずだ。
例題6A(ex6a.c)
![]()
#include <stdio.h>
#include <math.h>
main( )
{
int n,i ;
float x[100] ;
float sum,average ;
printf("データの件数を入れてください:") ;
scanf("%d",&n) ;
for (i=0 ; i<n ; i=i+1) {
printf("%d 番目のデータ:", i+1) ;
scanf("%f",&x[i]) ;
}
sum = 0 ;
for (i=0 ; i<n ; i=i+1) {
sum = sum + x[i] ;
}
printf("データの総和は %f です\n",sum) ;
average = sum / n ;
printf("平均値は %f です\n",average) ;
}
例題6Aの見所
- 配列の大きさは、データを入れるのに十分な数を用意しておく(例題では100)。
- 配列の要素は、0番目から始まる。それに対応して、ループ変数の
iを0からn-1まで動かしている。 - 何番目のデータかを表示する際、「0番目」という表現は多少違和感があるので、
i+1の値をプリントするようにしてある。
練習:標準偏差の計算
例題6Aを発展させて,平均値だけでなく標準偏差も計算して,両方を表示するプログラムを書いてみなさい。 標準偏差の計算方法については、すでに、総和のパターンの練習のところで説明済である。
解説: 分散(標準偏差)の推定
調査や実験から $n$ 個のサンプル $\{x_0, x_1, \cdots, x_{n-1}\}$ が得られたとしよう。 そのとき、サンプルの平均は $$ \bar{x}=\frac{1}{n} \sum_{i=0}^{n-1} x_i $$ で与えられる。一方、統計学の教科書を見ると、分散(不偏分散)$\sigma^2$は、 $$ \sigma^2 = \frac{1}{n-1} \sum_{i=0}^{n-1} \left( x_i - \bar{x}\right)^2 \tag{1} $$ であると書かれている(以下では、Cの配列の流儀に合わせて、添字は0から始める)。
ところが、以前の練習問題では、サンプルの分散(標本分散)を $$ s^2 = \frac{1}{n} \sum_{i=0}^{n-1} \left( x_i - \bar{x}\right)^2 \tag{2} $$ で計算していた。(1)式と(2)式では、分母のところが1だけ違っているが、どちらが「正しい」のだろうか?
平均$\mu$、分散$V$に従うような多量のデータの貯蔵庫があって、
観測の都度、そこから$n$個ずつデータを取り出すというイメージ。
ここの箇所、統計学の教科書には
$$
E\left[\frac{X_1 + \cdots + X_n}{n}\right] = \mu \\
Var\left[\frac{X_1 + \cdots + X_n}{n}\right] = \frac{V}{n}
$$
等と表記されているかもしれない。
いま、対象としているデータの「真の」平均(母平均)が$\mu$、「真の」分散(母分散)を$V$としよう。 そのとき、$n$ 個のデータ $\{x_i\}$ を独立に何回も取得(サンプリング)して得られたデータの平均値(標本平均)と真の値とのずれの2乗の期待値について $$ E\left[ \left( \frac{\sum_{i=0}^{n-1} x_i}{n} - \mu \right)^2 \right] = \frac{V}{n} \tag{3} $$ が成り立つことが知られている。 ここで、$E[\cdot]$ は $\cdot$ の期待値を表す。 (3)式は、『観測によって得た平均値は真の値の周りでばらついており、そのばらつきの程度はサンプル数$n$と共に$V/n$のように変化(減少)する』と言っているわけだ。
一方、データの本来の分散は、「真の平均値$\mu$からのずれ」を使って、 $$ \frac{1}{n} \sum_{i=0}^{n-1} \left( x_i - \mu \right)^2 $$
全てのデータが等しい重みでサンプルされるとすれば、この関係はほとんど自明であろう。
で評価できる。そして、$n$の多少にかかわらず、サンプルに渡ってこれを平均すれば$V$に等しくなるはずである: $$ V = E\left[ \frac{1}{n} \sum_{i=0}^{n-1} \left( x_i - \mu \right)^2 \right] \tag{4} $$
次に、上記の量$V$と、サンプルの平均を使って求めた分散(標本分散)の期待値 $$ \tilde{V} = E\left[ \frac{1}{n} \sum_{i=0}^{n-1} \left( x_i - \frac{\sum_{i=0}^{n-1} x_i}{n} \right)^2 \right] \tag{5} $$ との差((4)式ー(5)式)を計算してみると、 $$ V - \tilde{V} = E\left[ \left( \frac{\sum_{i=0}^{n-1} x_i}{n} \right)^2 \right] - 2 \mu \,\, E\left[ \frac{\sum_{i=0}^{n-1} x_i}{n} \right] + \mu^2 $$ が得られる。ところが、上式の右辺は、式(3)(データの平均値と真の値とのずれの2乗平均)の左辺を展開した式に他ならないので、結局 $$ V - \tilde{V} = \frac{V}{n} $$ となる。知りたかったのは$V$であるから、この式を変形して、 $$ V = \frac{n}{n-1} \tilde{V} = E\left[ \frac{1}{n-1} \sum_{i=0}^{n-1} \left( x_i - \frac{\sum_{i=0}^{n-1} x_i}{n} \right)^2 \right] \tag{6} $$
つまり、「分母を$n-1$」にして計算した分散は、その期待値が$V$に等しい、ということが分かった。
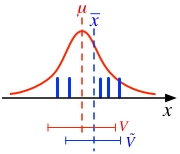
以上を定性的に再解釈すると
- サンプルデータは、真の平均と比較して、より大きな値、あるいはより小さな値に偏っている可能性がある。その程度は、サンプル数 $n$ が少ないほど顕著である。
- そうしたばらつきは本来分散に反映されなければならないが、例えば、値が「全体的に大きめ」であるようなサンプルに対しては、そのサンプル平均 $\bar{x}$ も 当然(真の平均より)大きめとなるので、$\bar{x}$ からの平均自乗距離(すなわち標本分散)は、真の平均 $\mu$ からの平均自乗距離よりも小さく見積もられてしまう。
- そうした偏り(bias)の効果まで勘定に入れて「補正」すると、分母のところが $n$ ではなく $n-1$ となる。
というわけである。