正規表現とテキスト処理
このページでは、TurtleEditを使って、正規表現を学んだり、テキスト処理を行う方法やヒントを紹介します。
文字と文字コード
基本的にコンピュータは数値(2進数)を扱う能力しかないので、「文字」という情報も、当然、数値に置き換えて処理しています。 我々が使っている多くの文字を分類し、文字毎に固有の番号(符号点(code point)、符号位置、等と呼ばれる)を与えるわけですが、これも決め事なので、いくつかの方式が存在します。 日本語については、現在、JIS規格(JIS X 0208)によるものと、Unicode規格によるものが使われており、最近の情報機器の殆どは後者を採用しています。
コードポイントのどの範囲に自国の文字を割り当てるかは、ある種の「戦争」のようです。 例えば、「ユニコード戦記」(小林龍生著・東京電機大学出版)を参照。
Unicodeは、その名称からも類推できるように、「統一コード」を目指して考案されたもので、その当初は、世界中の文字を16ビットの範囲で何とか表現してしまおうという、半ば強引なものでした。 アメリカのコンピュータ企業の世界展開を合理的に進めるための仕掛けとして導入されたわけです。 もちろん、世界中の文字が16ビット($2^{16} = 65536$)の範囲に収まるはずもなく、その後、21ビットの範囲に拡大されました。
文字に割り当てられたコードは、そのまま情報交換に使われるわけではありません。 情報のやりとりは、バイト(8ビット)を単位として行われるので、それに適したパターンに変換した上で用いられるわけです。 一般に「文字コード」と呼ばれているのは、この変換方式(符号化方式)のほうを指すことが多いようです。 漢字などを表すには、1文字あたり複数のバイトが必要になるため、こうした文字をマルチバイト文字と呼ぶことがあります。 TurtleEditでは、マルチバイト文字をオレンジ色の枠で囲い、区別して表示するようになっています。
JIS規格の文字セットをデータ交換に用いる際によく使われるのは、ISO-2022-JP(電子メールのやり取り等で使用。いわゆる「JISコード」)、 Shift JIS(Windows PC等で使用)、EUC(Unix等で使用)です。
一方、Unicodeに基づいた符号化方式としては、UTF-8がよく使われています(この方式では、日本語で使用する文字の殆どは1文字あたり3バイトを要します)。 その他、UTF-16と呼ばれる方式も、Javaの内部処理などに採用されています。
TurtleEditは、「実行」メニューの「設定」で指定した文字コード(Utf-8, EUC-JP, Shift_JISから選択)を使って、ファイルとの入出力、 および外部プロセスとのやり取りを行います。
正規表現
マイクロソフト社のWordにも、正規表現を使った検索や置換を行う機能が内蔵されています。 機能をオンにするには、「高度な検索と置換」を選んで、検索オプションで「ワイルドカードを使用する」にチェックを入れます。 詳しくはマニュアルなどを参照ください。
正規表現(regular expression)は、文字の並びのパターンを厳密に表現し、それを操作するための強力なツールです。 コンピュータ関係のみならず、「テキスト」を商売道具とする方ならば、覚えておいて決して無駄にならないはずです。
Akihabara, Akasaka, Akita, Arizona,... の共通点は、いずれも地名であることは別とすれば、Aで始まりaで終わる文字列である点です。 正規表現では、こうした文字列の全体を
A.*a
と表現します。
ピリオド.はワイルドカード文字で、「あらゆる文字のひとつ」を表します。
一方、アスタリスク*は、その左側の文字を任意の回数(0回も含む)繰り返したパターンを表します。
そうすると、.* は
(空っぽ) . .. ... ....
等々を全て表現していることになりますが、それぞれの.が任意の1文字にマッチするわけですから、kihabar, kasak, kit, rizon も当然 .* に含まれるわけです。
そして、それを A と a で挟み込めば、Aで始まり、aで終わる文字列(Aaも含む)の全てが形式的に表現できたことになります。
このように、正規表現は、「どのような種類の文字であるか」と「パターンの繰り返し回数」、加えて、集合操作を組み合わせることによって、文字列のパターンを曖昧さ無く表現する枠組みを提供します。
正規表現についての解説は、ネット上に沢山ありますし、書籍も出版されていますので、詳しくはそれらをご覧ください。 ここでは、ごく基本的な表記方法に限って、表にまとめておくだけにとどめます。 なお、TurtleEditはJava言語で書かれていることから、正規表現の仕様もJavaのそれに従っています。
| 記法 | 説明 |
|---|---|
.
|
全ての文字(1文字)にマッチ 英数字(いわゆる半角文字)も日本語文字も(文字の幅やバイト数に関係なく) 1文字は1文字として扱われる |
[文字のリスト]
|
リスト中の文字に含まれる1文字にマッチ[。、]は読点と句点のどちらかにマッチ[A-Za-z]はアルファベット(A,B,...Z,a,b,...z)のどれかにマッチここで - は文字の(文字コードとしての)範囲を表す
|
[^文字のリスト]
|
リスト中の文字以外の1文字にマッチ 例: [^0-9]は数字以外の文字にマッチ |
^ および $
|
^ は行の先頭、$ は行末にマッチ例: ^.*。$ 行末が句点で終わっている行にマッチ |
\p{InHiragana}
|
ひらがなにマッチ |
\p{InKatakana}
|
カタカナにマッチ |
\p{InCJKUnifiedIdeographs}
|
漢字にマッチ(中・日・韓国語の表意文字(ideograph)を統合したコード) |
文字*
|
「文字」を0回以上繰り返したパターンにマッチ |
文字+
|
「文字」を1回以上繰り返したパターンにマッチ |
文字{回数}
|
「文字」を「回数」だけ繰り返したパターンにマッチ 例: go{2}gle 文字{n,} で n 回以上マッチ、文字{n,m}でn回以上m回以下
|
文字*?
|
「文字」の0回以上の繰り返しパターンのうち、最短のものにマッチ 文字列 "abcabc" に対して、 .*c は "abcabc" にマッチするが、.*?c は "abc" それぞれにマッチする同様に、 文字+? や 文字{回数,}? という記法も可能
|
( 正規表現 )
|
丸括弧は正規表現パターンをグループ化し、n番目に現れたグループは 例: (a)(b)\2\1 は abba にマッチ。
|
候補1 | 候補2 | 候補3
|
候補の中のどれかに該当する文字列にマッチ。|は OR 演算に相当例: apple|orange|banana
|
\.
|
ワイルドカードとしてではなく、.という文字そのものこのように、正規表現で使われる記号を文字として表現したい場合は、 \(, \$, \( 等々のように、バックスラッシュを前に付ける |
正規表現を使った検索と置換
「フィルター」メニューの中の「正規表現フィルター」を選択すると、以下のようなダイアログが現れます:
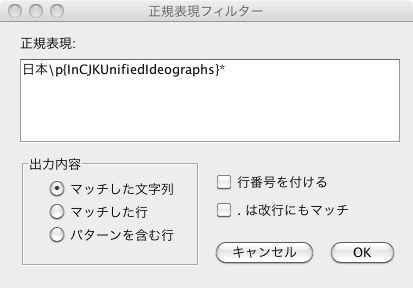
正規表現を記入して、 ボタンを押すと、その結果が下側の区画に表示されます。 正規表現に間違いがあると、エラーを示すダイアログが現れますから、内容をチェックします。
例えば、上記の例では、編集画面の中の「日本」で始まり、漢字が続くような単語、例えば「日本国憲法」、「日本男子」、「日本政府」・・・の様なリストが得られるわけです。
また、ダイアログの「出力内容」の設定を「マッチした行」にすると、正規表現に完全に一致した行が、また、「パターンを含む行」を選ぶと、そのパターンを含む(それぞれの文字列でなく)行全体が、出力されますので、目的に応じて切り換えておくようにします。
「フィルター」メニューから、「正規表現で置換」を選ぶと、以下のようなダイアログが現れます:
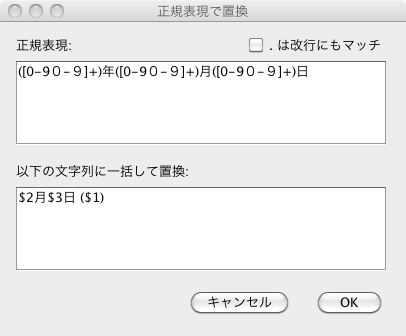
ダイアログの名称からすぐ察することができるように、これは、正規表現にマッチしたパターンを、下側の枠の文字列で置換するもので、編集テキスト全体に作用し、その結果がエディタ下側の区画に出力されます。
上の例では、"2011年3月11日" といったパターンの文字列を、順序を入れ替えて、 "3月11日 (2011)" に置き換えます。
ここで、置換文字列の中の $1, $2, $3 は、正規表現の中の丸括弧に挟まれたパターン(([0-90-9]+))に対応しており、数字は、丸括弧の登場した順序になります。
これを活用すると、非常に強力で柔軟なテキストの置換を行うことができます。
なお、置換したい文字列の中に$そのものが含まれる場合は、その箇所を \$ と表記します。
グループについての補足:
丸括弧付きの(正規表現)は「グループ」を表し、括弧内の正規表現にマッチしたパターンは記憶され、後から利用することができます。
これを(?:正規表現)と表記すると、マッチしたパターンは記憶されません(そのグループは前方参照の対象外となる)。
また、それに応じて、置換文字列中の $n の番号nの対応関係も変わります。
グループの番号は、括弧が現れた順に割当られます。括弧の中に括弧があるようなケース、例えば、(abc(def))では、$1は abcdef に、$2がdefに対応づけられます。
TurtleEditが他のエディタと異なるのは、検索や置換の結果が、編集中のテキストに直ちに反映されず、下側の区画に出力される点です。 置換の結果をもとに、さらに編集作業を進める場合は、フィルターメニューの一番下から「バッファーの交換」を選びます。 すると、下側の区画の内容が上側に(そして、上側は下側に)移動します。 下側の区画は、言わば、取り置き場、のようなイメージです。
【注意】バッファーが入れ替えられた状態でも、エディタは「同じファイルを編集中である」と認識していますので、「保存」すると、現在開かれているファイルは編集画面の内容で上書きされます。
外部コマンドを使ったフィルタリング
例えば、編集区画からある正規表現に合致するパターン(単語など)を抽出して、それをアルファベット順に並べ変えたり、出現頻度を調べたかったとしましょう。 TurtleEditの機能だけでこれらを行うことはできませんが、「外部コマンド」をうまく利用すると、案外と色々なことができてしまいます。
例えば、編集画面に単語のリストが並んでいる状態であったとします。 フィルターメニューから「外部コマンド実行」を選択すると以下のようなダイアログが現れます:
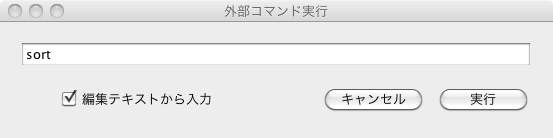
ここで、「編集テキストから入力」にチェックを入れ、コマンドをタイプしてをクリックする(またはEnterを押す)と、 編集画面のテキストがコマンドの標準入力に「流し込まれ」、処理結果が下側の区画に出力されます。 上は、各行を文字コード順に並べ変える(ソートする)例です。
こうしたやり方を応用して、『文章の中から漢字だけの並び(単語)を抽出し、それぞれの出現回数を得る』には、以下のように操作します(ここではUnix系のOSを想定):
- 編集画面にテキストを読み込む(ペーストする)
- 「正規表現フィルター」に
\p{InCJKUnifiedIdeographs}+を入力し、「マッチした文字列」を出力 - 「バッファを交換」する
- 「外部コマンド実行」で、「編集テキストから入力」にチェックを入れた状態で、
sortを実行 - 「バッファを交換」する
- 「外部コマンド実行」で、「編集テキストから入力」にチェックを入れた状態で、
uniq -cを実行
awkを覚えておけば、大抵のことは出来るようになります。
このように手順だけを並べると煩雑で面倒な印象を受けますが、「上の区画が処理されて下に出力」というパターンに慣れれば、案外と単純です。 すぐに役に立ちそうな外部コマンドには sort, uniq の他に、wc, cut, awk などが思い浮かびます。
なお、良く使うであろうsort, uniq, trの機能はエディタにも内蔵されており、フィルターメニューから起動することができます。
なお、コマンドの入力欄で、上下の矢印キーを押すと、これまで入力したコマンドを呼び出して再利用することができます。
コマンド入力欄では、一般的なシェルのように | を使ってパイプを繋いだり > でリダイレクトする処理には、残念ながら、対応していません。
ただし、外部コマンドとして陽にシェルを指定すればパイプを使うことは可能で、例えばUnix上でbashが使える場合は、
bash -c 'sort -r | uniq -c'
のように記述すれば、複数のステップを1行で記述できます。