Pythonプログラミング(ステップ7・統計的検定・正規性の検定)
このページでは、分布の正規性の検定方法について考える。
正規分布からの「ずれ」を可視化する:Q-Qプロット
我々が扱うデータの多くは、正規性を持つ(その分布が正規分布に従う)ことが知られている。 これはある意味でノーマル(normal)な性質と言えるが、もちろん、全てがそうであるというわけではない。 データセット $\{x_i\}$ が正規分布に従うかどうかを検定する方法は色々と知られているが、 ここでは、正規分布からの「ずれ」を直感的に把握するためによく使われているQ-Qプロットをまず紹介する。
2つの確率密度関数 $p(t)$ と $q(t)$ があるとき、それぞれの累積分布 $$ P(x) = \int_{-\infty}^x p(t) dt, \; Q(y) = \int_{-\infty}^y q(t) dt $$ を考える。 そして、$s = P(x) = Q(y)$ となるような $(x(s), y(s))$ の組を考える。 このとき、2つの分布が等しければ、当然、$x(s) = y(s)$ となる。 $x$を横軸、$y$ を縦軸にプロットすると、この関係は斜め45度の直線を表す。 そして、もし分布に食い違いがあれば、その直線からのずれとして図上に現れるはずである。
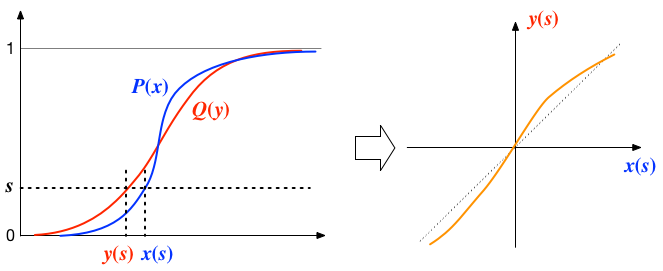
$n$個のデータ $x_i$ $(i=0,\cdots,n-1)$ が正規分布に近い分布をしているかどうかを見るには、 サンプルの累積度数と、正規分布の累積分布とを比較すればよい。具体的な手順は
一般に、Q-Qプロットでは横軸に標準正規分布、縦軸にデータを取る。
サンプルの累積確率密度は階段状に不連続になるので、$s=(i+1/2)/n$として、ステップの中間点を代表値として用いる。
- 【前処理1】あらかじめデータ $\{x_i\}$ を昇順に並べ替え、
- 【前処理2】平均0、標準偏差1に規格化しておく。
- $i$について以下を繰り返す:
- $i$番目のデータについて $s=(i+1/2)/n$ とおく。
- $s = \frac{1}{\sqrt{2\pi}} \int_{-\infty}^{y} e^{-t^2/2} dt$ となるような$y$を求める。
- $(y, x_i)$をプロットする。
となる。そのPythonコードの例を以下に示す:
右のコード例では、ソーティング、平均、分散、規格化等をNumPyの機能を使って行っている。 また、標準正規累積分布の逆関数の計算は Scipy の統計機能(scipy.stats.norm)を用いている。 詳しくは、マニュアル等を調べてみること。
# coding: utf-8
import matplotlib.pyplot as plt
import math
import numpy as np
from scipy.stats import norm
sample = [
174,175,180,185,178,184,179,185,170,178,184,183,180,191,180,180,174,188,181,182,
187,178,175,177,185,178,175,175,174,169,174,173,185,178,180,180,183,191,179,178,
174,185,185,180,193,181,178,181,177,176,174,180,186,180,180,180,185,174,194,175,
183,176,192,185,186,193,171,172,175,186,180,172,175,175,177,181,178,180,176,174
]
n = len(sample)
x = np.sort(np.array(sample)) # リストをNumPyデータに変換後、昇順にソート
mu = np.mean(x) # xの平均を計算
std = np.std(x) # xの標準偏差を計算
x = (x-mu)/std # 配列xの要素それぞれに対して mu を引いて、stdで割る
rv = norm()
qnormal=[ ]
qsample=[ ]
for i in range(n):
q1 = x[i]
s = (i+0.5)/n
q2 = rv.ppf(s)
qsample.append(q1)
qnormal.append(q2)
plt.title("Q-Q PLOT")
plt.plot(qnormal, qsample, '.', color=(1.0,0,0.0), linewidth=1.0)
plt.plot([-3, 3], [-3, 3], '-', color=(0,1,1))
plt.xlim(-2.5,2.5)
plt.ylim(-2.5,2.5)
plt.xlabel("NORMAL DISTRIBUTION")
plt.ylabel("SAMPLE")
plt.grid(True)
plt.show()

KS検定
Q-Qプロットを使うと分布の差を直感的に把握することができるものの、その「ずれ」を定量的に表現するにはどうしたら良いだろうか。 ここでは、そうした例として、Kolmogorov-Smirnov検定(KS検定)によって、実際のデータを調べてみよう。
正規分布を仮定して、パラメータを推定する
$n$個のサンプル $x_i$ ($i=0,1,\cdots,n-1$)から、平均の推定値 $$ \mu = \frac{1}{n} \sum_{i=0}^{n-1} x_i $$ および、不偏分散 $$ V = \sigma^2 = \frac{n}{n-1} \left( \frac{1}{n} \sum_{i=0}^{n-1} {x_i}^2 - \mu^2 \right) $$ を計算する。 そして、実際のサンプルが、正規分布 $N(\mu,\sigma^2)$とどれくらい違っているかを調べるステップに進む。
データを小さい順に並べ変え、正規分布との差を、累積分布の上で比較する
数学ライブラリを使う場合は、
import math
を忘れずに記入。
ここでは、正規分布そのものではなく、その累積分布を考え、それとデータとの「ずれ」を考える。その、基準となる正規分布の累積分布
$$
F(x) = \frac{1}{\sqrt{2\pi\sigma^2}} \int_{-\infty}^x \exp\left( - \frac{(t - \mu)^2}{2 \sigma^2} \right) dt
$$
が計算の過程で必要となるが、Pythonの標準的な数学ライブラー関数には誤差関数
$$
\textrm{erf}(x) = \frac{2}{\sqrt{\pi}} \int_0^x \exp\left(- t^2 \right) dt
$$
が含まれているので(math.erf())、それを使って、
$$
F(x) = \frac{1}{2} + \frac{1}{2} \textrm{erf}\left( \frac{x - \mu}{\sqrt{2} \sigma} \right)
$$
と求めることができる。
では、これと比較すべきデータ点の累積分布はどう考えれば良いだろう。 データ点が$n$個あったとすると、分布の上では$x_i$の位置で$1/n$ずつの寄与となる。 ($n$点の寄与をすべて足し合わせると、1にならなければならない)。 それを累積すると、下図の赤線のように、$x_i$の位置で段差が$1/n$の折れ線になる。 この赤線と、上記の$F(x)$のずれに着目するわけである。
オレンジ色の線がデータの分布関数、赤色がその累積を表す。
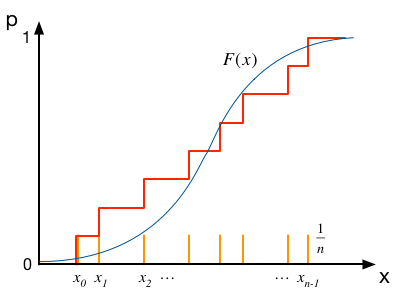
データから、その累積分布を求める手順は以下のとおりである。
まず、ソーティングのアルゴリズムを使って、$x_i$を小さい順に並べ変える。 記号が煩雑になるのを避けるため、ここでは、$x_i$はすでに小さい順に並べ変えらえた状態($x_0 \le x_1 \le \cdots \le x_{n-1}$)にあるとして、話しを進めることにする。
すると、$i$番目の点で$p$の値は(縦軸の0から1までの区間が$n$個の点によって$n$等分されている点に注意すると)、$p_i = \frac{i+1}{n}$ となる。
分布の「ずれ」を評価する
ふたつの累積分布のずれを定量的に見積もるため、各点での縦軸方向の差を調べる。$i$番目の点$x_i$での差は、ステップの下と上で、それぞれ $$ \begin{eqnarray} D_i^- = \frac{i}{n} - F(x_i), \\ D_i^+ = \frac{i+1}{n} - F(x_i) \end{eqnarray} $$ である。それらの中で最も大きくずれているところの絶対値を $$ D = \max_i \left\{ \max \left( |D_i^-|, |D_i^+| \right) \right\} $$ としよう。 このずれが、「もともと分布が$F(x)$であったところからのランダムな変動によって生じたものかどうか」 をテストするのがKS検定の考え方である。
$Q(x)$は、$x \to 0$で1に、$x$の増加とともに単調に減少し、$x \to \infty$で$0$となるような関数。
ここで、関数$Q$を $$ Q(x) = 2 \sum_{j=1}^{\infty} (-1)^{j-1} \exp\left(-2j^2 x^2\right) $$ で定義すると、 「ずれ」$D$が観測されたときに、「データは元々$F(x)$に由来するものである」という帰無仮説は、(近似的に)有意水準 $$ P(D) = Q\left( \left[\sqrt{n} + 0.12 + \frac{0.11}{\sqrt{n}} \right] D \right) $$ で棄却される(詳細は専門書を参照)。 言い換えれば、検定の有意水準を$\alpha$に設定した場合、$P(D) \gt \alpha$ならば、帰無仮説(分布は$N(\mu,\sigma^2)$)は棄却されない。
 練習:KS検定
練習:KS検定
$n$個のサンプル$x_0, x_1, \cdots, x_{n-1}$を入力すると、KS検定によってデータの正規性をチェックし結果を出力するプログラムを作成せよ。
別ページの練習問題で用いたプロ野球球団の選手の体重、身長、年収のうち、正規性が見られると考えられるものはどれか。