Pythonプログラミング(ステップ7・パラメータの最尤推定)
このページでは、ガウス分布の場合を中心に、モデルパラメータの最尤推定について考える。
ガウスモデルの平均と分散
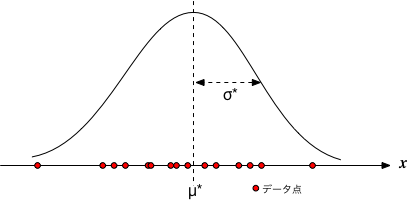
あらじめガウス分布することが予想されているデータ $X = \{ x_0, x_1, x_2, \cdots, x_{N-1} \}$ が得られたとしよう。 $N$個のデータが互いに独立であるとき、分布の平均$\mu$と分散$\sigma^2$を推定したい。
† 一般に、確率とは事象(見本の集合)が生起する割合を表すが、尤度(likelihood)は仮定がどのくらいありそうなのかを表す率で、 区別されるべきものであるが、このサイトの説明中ではどちらも「確率」と書いてしまっている箇所がある。
仮に、平均が$\mu$、分散が$\sigma^2$とすれば、そのとき、$x$という値が得られる確率を考えると、 $$ p(x | \mu,\sigma)=\frac{1}{\sqrt{2\pi} \sigma} e^{-\frac{(x-\mu)^2}{2\sigma^2}} $$ となる。 そうすると、$N$個のデータが得られる確率、すなわち、データ全体についての結合確率は、独立事象を仮定しているのだから、 $$ P(X|\mu,\sigma)=\prod_{i=0}^{N-1} p(x_i | \mu,\sigma) $$ となる。 この確率†は、あるモデルのもとで、そのデータセットが得られる尤もらしさ(尤度)を表す。
尤度を議論する際には、その対数(対数尤度)を用いるのが、いろいろと便利である。ガウス分布の場合は $$ L(X|\mu,\sigma) = \log P(X|\mu,\sigma) = - \frac{N}{2} \log(2\pi)- N \log(\sigma) - \frac{1}{2 \sigma^2} \sum_{i=0}^{N-1} (x_i - \mu)^2 $$ となる。
この場合、対数尤度を最大にするような$\mu^*$と$\sigma^*$は $$ \begin{eqnarray} \frac{\partial L}{\partial \mu} & = & 0 \\ \frac{\partial L}{\partial (\sigma^2)} & = & 0 \\ \end{eqnarray} $$ から、 $$ \begin{eqnarray} \mu^* & = & \frac{1}{N} \sum_{i=0}^{N-1} x_i \\ (\sigma^*)^2 & = & \frac{1}{N } \sum_{i=0}^{N-1} (x_i - \mu^*)^2 \end{eqnarray} $$ すなわち、標本平均と標本分散となる。
2変数のガウス分布
ガウス分布を高次元に拡張する手始めとして、2変数$(x,y)$の場合を考えてみよう。 ただし、以下では簡単のため、平均が0の場合に限ることにする。
確率密度を $$ p(x,y) = \frac{1}{Z} \exp\left[ - \frac{a x^2 + 2b x y + c y^2}{2} \right] $$ とおいて、 $$ Z = \int_{-\infty}^{\infty} \int_{-\infty}^{\infty} p(x,y) dx dy $$ となるよう、規格化定数$Z$を与えておく。
パラメータ $a,b,c$によって分布の形は変化するが、見通しをよくするために、行列 $$ A = \begin{pmatrix} a & b \\ b & c \\ \end{pmatrix} $$ を定義すると、 $$ f(x,y) = a x^2 + 2b x y + c y^2 = \begin{pmatrix} x & y \end{pmatrix} A \begin{pmatrix} x \\ y \end{pmatrix} $$ $A$が対角化できる、すなわち$A$の固有ベクトルから構成される直交行列$P$を使って、 $$ P^{-1}A P = \begin{pmatrix} \lambda_1 & 0 \\ 0 & \lambda_2 \\ \end{pmatrix} $$ と変換できることを使うと(ここで$P^{-1}=P^\top$)、座標変換 $$ \begin{pmatrix} u \\ v \end{pmatrix} = P^{-1} \begin{pmatrix} x \\ y \end{pmatrix} $$ によって、クロスする項の無い形 $$ \begin{pmatrix} x & y \end{pmatrix} A \begin{pmatrix} x \\ y \end{pmatrix} = \begin{pmatrix} u & v \end{pmatrix} P^{-1} A P \begin{pmatrix} u \\ v \end{pmatrix} = \lambda_1 u^2 + \lambda_2 v^2 $$ が得られる。

これらを踏まえ、$P$による座標変換は「回転」操作で「伸縮」が無いことを考慮すると($|P|=1$なので、$dx dy = |P| du dv = du dv$)、座標変換後の確率密度は $$ p(u,v) = \frac{1}{\sqrt{2 \pi / \lambda_1}} \frac{1}{\sqrt{2 \pi / \lambda_2}} \exp\left[ - \frac{\lambda_1 u^2 +\lambda_2 v^2 }{2} \right] $$ と書けるが、ここで、 $$ \lambda_1 \lambda_2 = | A | $$ であることを使うと、$(x,y)$の確率密度は $$ p(x,y) = \frac{1}{2\pi \big/ |A|^{1/2}} \exp\left[ -\frac{1}{2} \begin{pmatrix} x & y \end{pmatrix} A \begin{pmatrix} x \\ y \end{pmatrix} \right] $$ と書ける。そして、変数が2以上の場合でも全く同様に、(平均0の)$m$変数ガウス分布は次の形式で表現することが可能である: $$ p(\boldsymbol{x}) = \frac{1}{\left(2\pi\right)^{m/2} \big/|A|^{1/2} } \exp\left(-\frac{1}{2} \boldsymbol{x}^\top A \boldsymbol{x} \right) $$
多変数のガウス分布の尤度
前節を踏まえると、$m$変数のガウス分布(ただし平均は0)について、 $N$点のデータ $\boldsymbol{x}_i$ に対する対数尤度は $$ L(\boldsymbol{x}|A) = - \frac{N m}{2} \log (2\pi) + \frac{N}{2} \log(|A|) - \frac{1}{2} \sum_i \boldsymbol{x}_i^\top A \boldsymbol{x}_i $$ となる。 以下では、この対数尤度を最大にする $A$ の表式を導く。
準備
対数尤度の式中で、$A$に依存する項の、配列要素についての微分について考える。 まず、右辺第二項目を、行列要素で偏微分すると $$ \frac{\partial \log |A|}{\partial a_{i,j}} = \frac{1}{|A|} \frac{\partial |A|}{\partial a_{i,j}} $$ となる。 ここで、$A$の行列式を余因子 $C_{i,\ell}$ で展開し $$ |A| = \sum_{\ell} a_{i,\ell} C_{i,\ell} $$ これを $a_{i,j}$で微分することで、 $$ \frac{\partial |A|}{\partial a_{i,j}} = C_{i,j} $$ となることから、 $$ \frac{\partial \log |A|}{\partial a_{i,j}} = \frac{1}{|A|} C_{i,j} $$ を得る。
ここで、行列のスカラー関数$f(A)$の行列による微分 $$ \frac{\partial f(A)}{\partial A} $$ を、それぞれの要素が $$ \left\{ \frac{\partial f(A)}{\partial A} \right\}_{i,j} = \frac{\partial f(A)}{\partial a_{i,j}} $$ となるような行列として定義することにする。 そして、逆行列の余因子行列による表現を思い出すと、 $$ \frac{\partial \log |A|}{\partial A} = (A^{-1})^\top $$ と表現することができる。
次に、 $$ \frac{\partial}{\partial a_{i,j}} \boldsymbol{x}^\top A \boldsymbol{x} = \frac{\partial}{\partial a_{i,j}} \sum_{k,\ell} a_{k,\ell} x_k x_\ell = x_i x_j $$ であることから、対数尤度の3番目の項の微分は $$ \frac{\partial}{\partial A} \sum_i \boldsymbol{x}_i^\top A \boldsymbol{x}_i = \sum_i \boldsymbol{x}_i \boldsymbol{x}_i^\top $$ となることがわかる。
対数尤度の最大化
以上より、対数尤度が最大になるための必要条件 $$ \frac{\partial L(\boldsymbol{x}|A)}{\partial A} = \frac{N}{2}(A^{-1})^\top - \frac{1}{2} \sum_i \boldsymbol{x}_i \boldsymbol{x}_i^\top = 0 $$ から、$A$は $$ (A^{-1})^\top = \frac{1}{N} \sum_i \boldsymbol{x}_i \boldsymbol{x}_i^\top $$ ここで、右辺はデータの共分散行列 $$ S = \frac{1}{N} \sum_i \boldsymbol{x}_i \boldsymbol{x}_i^\top $$ に他ならないことと、$C$は対称行列であることから、対数尤度が最大になる条件 $$ A^* = S^{-1} $$ を得る。
平均が0でない場合
ここまでは、平均が0の場合を考えたてきたが、一般の場合は、各変量の平均が$\boldsymbol{\mu}$ とすると、尤度を $$ p(\boldsymbol{x}) = \frac{1}{\left(2\pi\right)^{mN/2} |S|^{N/2} } \exp\left(-\frac{1}{2} \sum_i (\boldsymbol{x}_i-\boldsymbol{\mu})^\top S^{-1} (\boldsymbol{x}_i -\boldsymbol{\mu}) \right) $$ と置いて、同様の議論が可能である(ここで、$|S^{-1}| = 1/|S|$)。 このとき、尤度を最大化する$\boldsymbol{\mu}$は $$ \boldsymbol{\mu}^* = \frac{1}{N} \sum_i \boldsymbol{x}_i $$ および $$ S = \frac{1}{N} \sum_i (\boldsymbol{x}_i -\boldsymbol{\mu}^*) (\boldsymbol{x}_i-\boldsymbol{\mu}^*)^\top $$ である。