情報基礎A 「Cプログラミング」(ステップ7・最小二乗法・理論編)
このページでは、データに直線を当てはめる際の考え方と計算方法について考える。
揺らぎや誤差のあるデータの集まり
ある量 $X$ と、別の量 $Y$ の関係を知りたいことはよくある。例えば、$X$として、その月の平均気温、$Y$ としては、アイスクリームの購買金額、といった具合だ。 もし $X$ と $Y$ に関係性を見出すことができれば、気温($X$)を知ることで消費量が予想できるので、仕入れ量をうまく調整することができるようになるかもしれない。
$X$にも揺らぎがある場合は、以下の話は少し(かなり)変わってくる。
ここで、$X$ はいつも十分正確に測ることができて、誤差は無視できるとしよう。その上で、$X$ と $Y$ の間には、直線的な関係性 $$ Y = a X + b + \xi $$ が成り立つと仮定する。ここで、$a$と$b$はある定数、$\xi$ は誤差や揺らぎを表す「ランダムな数」である。
なぜ、$\xi$ などという量を考えなければいけないのか?
もし $\xi$ が無ければ(あるいは$\xi=0$ならば)、上の関係式は、単なる比例関係にすぎず、$X$が決まれば、$Y$は一意に決まってしまう。 しかしながら、例えば、アイスクリームの売り上げを考えてみると、気温が同じだからと言って、売り上げが多いときも少ないときもあるはずだ。 これに限らず、$X$ だけでは完全に決まらない要因によって、$Y$ の値が揺らぐ場合がほとんどだ。 その揺らぎを $\xi$ という記号で表してみよう、ということである。
ここで、$\xi$ は、サイコロの目のように、$X$ を測るたびにコロコロと変わると考える。あるときは +1.4, またあるときは -0.5 $\cdots$といった具合に。
以下では、$i$ 回目に測った $X$ の値を $x_i$、そのときの $Y$ の値を $y_i$、そして揺らぎを $\xi_i$ と表記することにしよう。
ガウス型の確率分布
揺らぎの成分 $\xi$ が「ランダム」だとすると、何ともとらえどころの無い話しになってしまうが、ここでは、沢山の計測や試行を行って $\{ \xi_i \}$ の性質を見たときに、それが、平均 0 , 分散 $\sigma^2$ のガウス分布に従っている(あるいは従うべきである)と考える。 事実、ある平均的な値からの散らばり具合がガウス分布(正規分布)でよく表現できるような事象は、試験の点数の分布など、あらゆるところに登場する、 ある意味で普遍的な性質と言ってよい。
$\Delta$を微小量として、連続量$\xi$が、$(\xi_i, \xi_i + \Delta)$の間に見出される確率が $P(\xi_i) \Delta$
量 $\xi$ がガウス分布に従うとすると、$\xi=\xi_i$であるよう事象が発生する確率密度は $$ P(\xi_i) = \frac{1}{\sqrt{2\pi \sigma^2}} \exp\left(-\frac{{\xi_i}^2}{2 \sigma^2} \right) $$ で表すことができる(平均は0の場合を考えている)。
ここで、さきほど仮定した「比例関係+揺らぎ」の式を見直してみると、データ$(x_i, y_i)$毎に $$ \xi_i = y_i - a x_i - b $$ が成り立つというわけであるから、上記の確率密度の式は、($a$ と $b$ の値を与えた際に)データ$(x_i, y_i)$が見出される確率が $$ P(x_i,y_i) = \frac{1}{\sqrt{2\pi \sigma^2}} \exp\left(-\frac{(y_i - a x_i - b)^2}{2 \sigma^2} \right) $$ で与えられる、という風に解釈することも可能だ。
最もらしさの度合い(尤度)
ここまでの議論で、比例関係を決める $a$ と $b$ の値については何も言及しなかった。が、ここで知りたいのは、もちろん、データセット$\{(x_i,y_i)\}$ が与えられた場合に、そのデータの「傾向」を良く表すような $a$ と $b$ をどのように推定すればよいか、である。 そんなときに、「尤もらしい」指針は、以下のようなものであろう:
データ $(x_i,y_i)$ を確率密度の式$P(x_i,y_i)$に入れてみたとき、その確率が最大になるように $a,b$ を決める
ここでは、データ点が複数(以下では $i=1,2,3,\cdots,n$ の $n$ 個)ある場合を考えているから、そのようなデータの集まりを見出す確率(これを尤度と呼ぶ)は、 揺らぎ(誤差)によるランダムな変動が確率的に独立だと仮定すれば、それらの積 $$ P(\{(x_i,y_i)\}) = P(x_1, y_1) P(x_2, y_2) \cdots P(x_n,y_n) $$ となる。 そして、この確率は $a,b$ の値に依存している、というわけである。 そのことを陽に表すため、以降ではこの量(データ集合を見出す確率、尤度)を $P\left(\{(x_i,y_i)\} \middle|a,b \right)$ と表記することにしよう。
尤度の最大化
右の議論では、$Y$の分散($\sigma^2$)は$X$によらず一定、と仮定されているが、 そうでない場合(揺らぎや誤差が測定点ごとに異なる場合等)もあるだろう。 詳しくは「重み付き最小二乗法(weighted least squares regression)」等をキーワードに調べてみるとよい。
尤度 $P\left(\{(x_i,y_i)\} \middle|a,b \right))$ がガウス分布に従うような場合、それを最大化するような $a,b$ を求めるのは、案外と簡単である。 尤度関数は $P(x_i, y_i)$ の積で与えられるが、指数関数の基本的な性質 $$ \exp(A) \exp(B) = \exp(A+B) $$ を使うと、式は $$ P(\{(x_i,y_i)\}|a,b) = \left(\frac{1}{\sqrt{2\pi \sigma^2}}\right)^n \exp\left[-\frac{\sum_i^n (y_i - a x_i -b)^2}{2 \sigma^2} \right] $$ と変形できる。 すると、この尤度を最大化するような $a,b$ を決めるということは、指数関数の中の $$ \sum_i^n (y_i - a x_i -b)^2 $$ を最小化することに他ならない。 つまり、上記の総和を最小化するような $a,b$ こそが、仮定しているモデルとデータ集合からみて、いちばん尤もらしい値である、ということが分かった。
最小二乗法
次に、$a,b$ の関数 $$ F(a,b) = \sum_i^n (y_i - a x_i -b)^2 $$ を最小化する具体的な方法について考えてみよう。このプロセスは、二乗した和を最小化することから、一般に最小二乗法(least-square method)と呼ばれている。 この関数の振る舞いの感触を得ておくために、二乗のところを展開して、$a,b$を総和の外側に出すと、 $$ F(a,b) = a^2 \sum_i^n {x_i}^2 + b^2 n + 2 a b \sum_i^n x_i - 2 a \sum_i^n x_i y_i - 2 b \sum_i^n y_i + \sum_i^n {y_i}^2 $$ となる。一見複雑そうに見えるけれども、総和の箇所を $$ S_{xx}=\sum_i^n {x_i}^2, \ S_{xy}=\sum_i^n x_i y_i, \ S_y=\sum_i^n y_i, \ S_{yy}=\sum_i^n {y_i}^2 $$ のように記号で置き換えて、式を整理すると $$ F(a,b) = S_{xx} a^2 + n b^2 + 2 S_x a b - 2 S_{xy} a - 2 S_y b + S_{yy} $$ のように、$a, b$についての二次式になっている。 これを最小化するような $a,b$ の組を見つければよいわけだ。
変数変換と二次形式の極値
$F(a,b)$が最小になるような$a,b$を見つけるため、ここで、変数変換(原点をずらす座標変換) $$ \alpha = a - a^*,\\ \beta = b - b^* $$ を施して、$F$を、$\alpha,\beta$の二次形式 + 定数、 $$ F(\alpha,\beta) = A \alpha^2 + B \alpha \beta + C \beta^2 + D $$ の形に書き直してみよう。 この式の形(あるいは$F(\alpha,\beta)$が表す曲面の形状)から、$\alpha=\beta=0$ で $F(\alpha,\beta)$ が極値を取ることは明らかである。
$F(\alpha,\beta)$ は、右図のような下に凸な形をしており、$\alpha,\beta=0$ で最小となる。
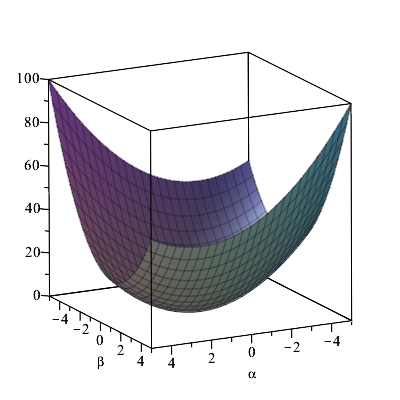
$F(a,b)=F(\alpha,\beta)$とおいて式を展開し、係数を比較すると、 $$ A = S_{xx},\\ B = 2 S_x , \\ C = n $$ であることがすぐにわかる。このとき、$A,C>0$ であるから $F(\alpha,\beta)$は下に凸な形状で、$\alpha=\beta=0$ は極小値(最小) を与える点である。さらに、$a^*,b^*$ についての連立方程式 $$ \left( \begin{array}{cc} S_{xx} & S_x \\ S_x & n \end{array} \right) \left( \begin{array}{c} a^* \\ b^* \end{array} \right) = \left( \begin{array}{c} S_{xy} \\ S_y \end{array} \right) $$ が得られ、これを解くと、 $$ a^* = \frac{n S_{xy} - S_x S_y}{n S_{xx} - {S_x}^2} ,\\ b^* = \frac{S_{xx} S_y - S_{xy} S_x}{n S_{xx} - {S_x}^2} $$ つまり、$a=a^*, b=b^*$で、$F(a,b)$の値が最小になることがわかった。 これが、$X$ と $Y$ の関係を一次式でモデル化した際に、尤度を最大化する(一番尤もらしい)$a,b$ の値ということになる。
微分を使った導出
上記の説明は少し回りくどいと感じられるかもしれない。極値を与えるような点を求めるだけなら、微分を使うのが簡単であろう。 すなわち、 $$ \left. \frac{\partial F(a,b)}{\partial a} \right|_{a=a^*,b=b^*}= 0,\\ \left. \frac{\partial F(a,b)}{\partial b} \right|_{a=a^*,b=b^*}= 0, $$ となるような $a=a^*, b=b^*$ を求めればよい。
実際に $F(a,b)$ を微分して0と置いてみると $$ 2 S_{xx} a^* + 2 S_x b^* - 2 S_{xy} = 0,\\ 2 n b^* + 2 S_x a^* - 2 S_y = 0, $$ となるが、(当然ではあるが)これは上の節で登場した $a^*,b^*$ の連立方程式と全く同じ式となる。
直線に対する最小二乗法の公式
以上で、データセット$\{(x_i,y_i)\}$ が与えられたときの、直線モデルの勾配 $a$ と切片 $b$ の推定方法が分かったわけだが、$a^*,b^*$ を与える式の分子と分母を $n^2$ で割った $$ a^* = \frac{(S_{xy}/n) - (S_x/n) (S_y/n)}{(S_{xx}/n) - {(S_x/n)}^2} ,\\ b^* = \frac{(S_{xx}/n)(S_y/n) - (S_{xy}/n)(S_x/n)}{(S_{xx}/n) - {(S_x/n)}^2} $$ を眺めてみる。 すると、この式中、例えば $S_{xy}/n$ は、データに対する $XY$ の平均に他ならない。 そこで、これを「$XY$の期待値(expected value)」という意味を込めて $E(XY)$ と表記することにする。 (もちろん、その内実は、$x_i y_i$ の総和をデータ数 $n$ で割った値であることに違いはない)。 すると、$a,b$ の推定の式中に現れる全ての量は、$X, XY, X^2, Y$ の平均値を使って表すことができて、 教科書などによく登場する $$ a^* = \frac{E(XY) - E(X) E(Y)}{E(XX) - E(X)^2} ,\\ b^* = \frac{E(XX) E(Y) - E(XY) E(X)}{E(XX) - E(X)^2} $$ が得られる。
ここで、回帰直線の勾配($a$)は、「$X$と$Y$の共分散 ÷ $X$の分散」で与えられることがわかる。
こうして得られたパラメータの推定値の信頼度(誤差)について、こちらのページで考察する。