情報基礎A 「Cプログラミング」(ステップ9・ポインター・基本編)
このページでは「Cの難関」と言われている(多くの人がそう思っている)ポインターについて、その基本事項を学ぶ。
1.変数とアドレス
情報の管理方法には大きく分けて2種類ある。ひとつは、コンテンツそのものを保管する方法(例えば、本やCDなどの形で収蔵しておく)、そしてもう一つは、コンテンツがどこにあるかを管理する方法(図書館の蔵書カードはそれにあたる)である。 インターネット上の様々な情報にアクセスする際に用いるURI(Universal Resource Indicator)は、後者によって管理・アクセスを実現する手段のひとつと考えることができる。
この「コンテンツ(中身)」と「場所」の区別はC言語で扱うデータ(変数)についても当てはまる。 このことを念頭において、変数について、次の事項を確認しておこう:
- 変数とはデータを入れておくための「箱」であり、箱には「変数名」というラベルが付けられている。
- 箱の中身は、整数(int)、実数(float)、文字(char)などの種類があって、どれを使うかは変数を宣言するときに変数名と共に指定する。
- プログラム中に変数名を書くと、それは箱の中身のデータ(値)を表す。
変数を使うときに、コンピュータの内部では、主記憶装置(メモリー)の一部がその変数用に割り当てられ、プログラムはそこをアクセス(読み・書き)している。 全てのメモリーには、アドレス(番地)という通し番号が割り当てられていて、変数名は、そのアドレスと関連づけられている。 アドレスの単位はバイト(byte, 1 byte = 8 bit)である。 例えば、
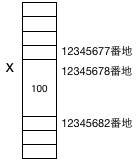
int x ; x = 100 ;
というコードの例では、Cコンパイラはまず変数 x にメモリー上のあるアドレスの区画を割り当てる。ここでは仮にそれを12345678番地としよう。
そして、代入x=100;によって、12345678番地の区画(箱)に、データが書き込まれるわけだ。
変数のアドレスは単なる数値である。
そこで、C言語には、アドレスという数値をデータとして扱う機能が備わっている。
変数xに割り当てられている区画のアドレスは、その変数名の前に&を付けて、&x で表現する。
そうすると、変数xのアドレス(を表す数値)をプリントするには
printf("%d\n",&x) ;
とすればよい。すると、この場合、画面には12345678が出力される。
実は、この変数名に&を付けるやり方は、scanf()関数を使う際に、すでに登場していた。
キーボードから変数xに数値を入力する際に
scanf("%d",&x) ;
と書くのは、「キー入力されたデータ(%d:整数の数値)を、&xで指定されるアドレスの区画に書き込むべし」
という指示に他ならない。
2.アドレスの操作とポインタ変数
C言語には、int型やfloat型等のデータの操作に加えて、アドレスというデータを操作するための機能が備わっている。 そうしたデータを操作するには、アドレスを記憶しておくための変数(メモリ)がどうしても必要になる。 そして、アドレス用の変数を、(「アドレス型の変数」とは言わずに)ポインター変数、あるいは単にポインターと呼ぶ習わしになっている。
ポインター変数は、それがどのような型のデータを指し示す(ポイントする)のか、とセットで宣言しなければならない。 例えば、整数型変数のアドレス操作のためのポインタ変数は
int * p ;
実数型変数のアドレス操作のためには
float * a ;
のように、型 * 変数名 ; というパターンで宣言する。
複数のポインタ変数をまとめて宣言するには型 * 変数名1, * 変数名2, ... ;とすればよい。
上の例では、それぞれpとaという名前で、アドレスを記憶するための「箱」が用意されたことになる。
*pや*aという変数が宣言されたわけではないことに注意。
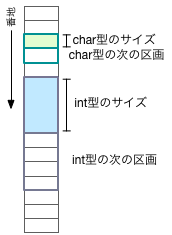
データの「単位」(バイト数)は sizeof(形名)で取得することができる。sizeof(int)は通常4を、sizeof(char)は通常1となる。
ポインタを使った計算において、気をつけなければいけない点がある。
それは、アドレス計算の「単位」が、扱うデータの型によって異なる点だ。
例えば、2つのポインタ変数int * ip ;とchar * cp ;を宣言したとして、
ip+1とcp+1とでは「増分」が異なるのだ。
変数ipはint型のポインタである。int型の変数は(OSにも依るが)通常4バイト(32ビット)のメモリを専有する。
その場合、iP+1 は、ipのアドレスの4バイト先のアドレス、と解釈されるのだ。
ip+8 ならば、int型で8個分先のアドレス、すなわち、ipから4*8=32バイト先、ということになる。
一方、char型の変数は、通常、メモリを1バイトしか専有しない。するとcp+1は、1バイト分だけ先のアドレス、と解釈される。
つまり、ポインタ変数を用いた計算は、自動的に、対象とするデータの基本サイズを勘定に入れた形で行われるようになっているわけだ。 このように、ポインタを使った演算の単位は、1バイトではなく、『変数1個分』がC言語のルールである。
ポインタ変数を用いた基本的な記法と用例を以下にまとめる:
| 記法 | 説明 | 例 |
|---|---|---|
型名 * 変数名 |
ポインタ変数の宣言。 |
int * p ; float *a, *b ; |
&変数名 |
その変数に割り当てられたメモリのアドレス。 &は変数のアドレスを意味する。 |
int x=10 ; int * p ; p = &x ; (pにはxのアドレスがセットされる) |
*ポインタ変数名 |
ポインター変数の前にアスタリスク * を付けると、 「ポインタ変数にセットされているアドレスに記憶 されているデータ」を表す。 *はポイントされている先の値を意味する。 |
int x=10 ; int y ; int * p ; p = &x ; y = *p ; (yには10がセットされる) |
ポインタ変数名 + 整数 |
「ポインタ変数が指すアドレスから、整数個分だけ後ろの アドレス」を表す。 |
int x[3]={1,2,3} ;
int * p, * q ;
p = &x[0] ;
q = p + 2 ;
(qにはx[2]のアドレスがセットされる)
|
*(ポインタ変数名 + 整数) |
「ポインタ変数が指すアドレスから、整数個分だけ後ろの アドレスのデータ値」を表す。 |
int x[3]={1,2,3} ;
int y ;
int * p ;
p = &x[0] ;
y = *(p + 2) ;
(yには3セットされる)
|
配列変数名 |
配列変数に[ ]を付けずに、変数名だけを書くと、 配列先頭のアドレスを表す。 |
int x[3]={1,2,3} ;
int * p ;
p = x ;
(pには&x[0]がセットされる)
|
3.ポインタの出番
ポインタなどという面倒な仕掛けは何故必要なのだろうか。 ここでは、その理由を考える(想像する)糸口を得るため、あまり詳細には立ち入らず、いくつかの事例を紹介する。
関数の間でのデータの受け渡し
Cの関数の呼び出しy=func(x);のより詳細な動作について考えてみる。
呼び出し側の変数xの値は、関数funcの引数に宣言されたローカル変数の初期値として設定される(この動作を値渡しと呼ぶ)。
そして、そのローカル変数を関数内でいくら操作しても、基本的に呼び出し側には影響を及ぼさない。
であるから、
void func(int x)
{
x = 0 ;
}
のようなコードを書いて、func(y); のように呼び出したとしても、呼び出し側のyが0にセットされるわけではない。
ところが、引数をポインタ変数として定義することで、関数にアドレス(という値)を渡すこともできる。関数定義の引数のところを書き換え、
void func(int *x)
{
*x = 0 ;
}
とすると、呼び出し側が
int y=1 ; func(&y) ;
を実行した際、呼び出し側の変数yの値は0にセットされる。このように、関数にアドレスデータを渡す方式を参照渡しと呼ぶ。
C言語は基本的に値渡しをするように設計されているが、ポインタ変数を使うことで、実質的に参照渡しも可能としているわけだ。
すでにscanf()関数などで見たように、参照渡しを利用することで、データを参照したり変更する際の自由度が増す
(その反面、ちょっとしたミスで、おかしな動作するコードが簡単に書けてしまう)。
参照渡しを使うことによって、基本的なデータ型(char, int, float等)以外のデータでも、関数の間で受け渡すことが可能となる。 配列の受け渡しもその例のひとつと考えることができる。つまり、
void func(int a[]) { ... }
main()
{
int b[100] ;
...
func(b) ;
...
}
で、関数func()に渡しているのは、配列bの実体ではなく、その先頭のアドレスのみである。
いま普及しているコンピューターはフォン・ノイマン型アーキテクチャで、プログラムとデータを区別しない。
関数もメモリー上に置かれた機械語というデータに過ぎないから、関数へのポインタとして扱うことができる。 たとえば、数値積分を行ないその結果を返すような関数を設計するような場合、非積分関数を呼び出し側で変更できれば、柔軟性が増す。 そんな際に、関数へのポインターを使って
#include <math.h>
double integration(double a, double b, double (*func)(double))
{
...
}
main()
{
...
res4sin = integration(0.0, 1.0, sin) ;
res4cos = integration(0.0, 1.0, cos) ;
...
}
といった書き方が可能である。ここで、関数の引数の double (*func)(double)は『戻り値が doubleで、引数としてdoubleを持つような関数へのポインタ』を表す。関数へのポインターとは、その関数がメモリー上の置かれている機械語の先頭アドレスに対応する。
順番に並んだデータの操作
以上で見てきたように、ポインターとは、参照するメモリーの位置を記憶・操作するために用意された仕掛けである。 そうすると、メモリーの参照位置を順番に変えながら、同じパターンの処理を繰り返すような場合に、ポインタを活用することができる。 簡単な例で、その様子を見ておこう。
最初の例は、配列データのコピーである。ある配列の内容を別の配列にコピーするには、例えば、
int a[5]={1,2,3,4,5} ;
int b[5] ;
int i ;
for (i=0 ; i<5 ; i=i+1) {
b[i] = a[i] ;
}
のようなコードを書けばよい。これを敢えてポインターを使って書き換えると、
int a[5]={1,2,3,4,5} ;
int b[5] ;
int *ap, *bp ;
ap=a ; bp=b ;
int i ;
for (i=0 ; i<5 ; i=i+1) {
*bp = *ap ;
ap=ap+1 ; bp=bp+1 ;
}
となる。あるいは、ループのところを
for (i=0 ; i<5 ; i=i+1) {
*(bp+i) = *(ap+i) ;
}
としても良い。 もっとも、この例ではポインタを用いる利点は全く無いが・・
次の例は、文字配列strの各文字の文字コードを32ずつ減らす(ASCIIコードで、小文字を大文字に変換する)操作を、
空白文字('\0')が見つかるまで行なうコードの例である。
配列のアドレスをポインタ変数pにセットした後、whileループで、ポインタの指すデータ(文字コード)から32を減らし、
ポインタ変数の値を1増やす(参照先をひとつ進める)、を繰り返している:
char str[]="abcdefg" ;
char *p = str ;
while (*p != '\0') {
*p = *p - 32 ;
p = p + 1 ;
}
データ領域の動的な管理
処理を始めてみるまで、データのサイズ(配列変数の要素数等)が不明で、プログラムの実行時の初めて必要なメモリーサイズが わかるような例は多い。ところが、C言語では、配列の要素数は、プログラムの作成時に決めておかなけれればならない。
例えば、以下のように記述することで、float型の配列x[]の要素数を変数nの値によって「後から」設定することが可能となる:
#include <stdlib.h>
...
float *x ;
int n ;
...
n=1000 ;
x = (float *) malloc(sizeof(float)*n) ;
for (i=0; i<n; i=i+1) {
x[i] = ... ;
}
free(x) ;
malloc(),free()はCの標準ライブラリ関数のひとつ
上の例(不完全なCのコードではあるが)では、float型へのポインタ変数xをまず宣言している。
その後、malloc()関数を使って、float型の変数 n個分のメモリー領域を確保し、その先頭アドレスをxに代入する。
ここで、sizeof(変数の型)は、その型の変数1個分のメモリーサイズ(バイト数)を表す。
そうすると、xが指すアドレスには、sizeof(float)*nバイト分のメモリ領域が「空き地」として用意されるわけである。
malloc()関数の前に(float *)は、関数が返すアドレス(数値)をfloat型へのポインターと見なしてxにセットすることを明示するために必要である。
このように、一旦メモリー領域が確保できれば、x[何々](あるいは *(x+何々))のようにそこにアクセスすることが可能となる。
もうそのメモリーが必要無くなれば、free(x);によって、メモリー領域を「返納」しておく
(返納されたメモリーは、他のソフトウェアが使用できるようになる)。
関数の中でサイズの大きな配列を宣言しようとすると、コンパイルエラーになることがある。
関数には使えるメモリのサイズ(スタックメモリのサイズ)にかなりきつい上限が課せられているためだ。
そんなときには、動的メモリ確保の出番となる。
データの繫がりの表現
$a$は$d$を指し、$b$は$c$を指し、$d$も$c$を指し、$c$は$a$を指す、といった具合に、データの繫がり方が重要となるアルゴリズムも多い。 そのような際に、
struct graph {
int value ;
struct graph *link ;
} a,b,c,d ;
a.link = &d ;
b.link = &c ;
d.link = &c ;
c.link = &a ;
のように、ポインター(アドレス)を使った記述がよく行われる。
ここでstructは構造体と呼ばれ、データ構造を新しく定義する機能を持つが、ここではその詳細に立ち入らず、
ポインター型を使って自然にグラフ(graph)等のデータ構造が表現できること紹介するに留めたい。